


在国内⽐较常⽤的是utf8mb4_general_ci(默认)、utf8mb4_unicode_ci、utf8mb4_bin这三个。其中ci是 case insensitive, 即 “⼤⼩写不敏感”, a 和 A 会在字符判断中会被当做⼀样的,这样在需要判断⼤⼩时就不能满⾜要求了。
一、设置数据库支持
1、查看
show global variables like '%lower_case%';
# 查询结果,如下
Variable_name Value
lower_case_file_system OFF
lower_case_table_names 1
备注:lower_case_table_names的值,0代表区分,1代表不区分
2、设置(如果lower_case_table_names=0)
- 阿里云/腾讯云: 在数据库管理后台寻找“lower_case_table_names”,设置成1,重启;
- 自建数据库: Mysql配置文件中 /etc/my.cnf 添加参数并重启数据库
[mysqld] … lower_case_table_names = 1
二、设置库、表、字段字符集
1、查看当前变量以及对比区别
-
查看变量
SHOW variables LIKE '%char%'; # 也可以用这个语句 # SHOW variables WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%';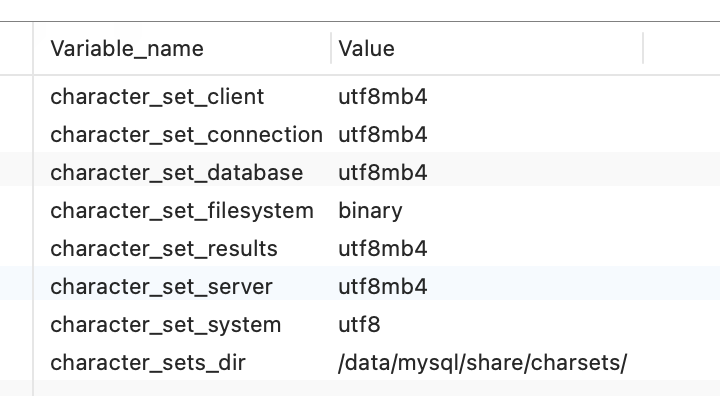
得到8个 character_set 变量:
- character_set_client:
主要用来设置客户端使用的字符集 - character_set_connection:
主要用来设置连接数据库时的字符集,如果程序中没有指明连接数据库使用的字符集类型则按照这个字符集设置 - character_set_database:
主要用来设置默认创建数据库的编码格式,如果在创建数据库时没有设置编码格式,就按照这个格式设置 - character_set_filesystem:
文件系统的编码格式,把操作系统上的文件名转化成此字符集,即把character_set_client转换character_set_filesystem, 默认binary是不做任何转换的 - character_set_results:
数据库给客户端返回时使用的编码格式,如果没有指明,使用服务器默认的编码格式 - character_set_server:
服务器安装时指定的默认编码格式,这个变量建议由系统自己管理,不要人为定义 - character_set_system:
数据库系统使用的编码格式,这个值一直是utf8,不需要设置,它是为存储系统元数据的编码格式 - character_sets_dir:
这个变量是字符集安装的目录
在启动mysql后,我们只关注下列变量是否符合我们的要求
- character_set_client
- character_set_connection
- character_set_database
- character_set_results
- character_set_server
下列三个系统变量我们不需要关心,不会影响乱码等问题
- character_set_filesystem
- character_set_system
- character_sets_dir
- character_set_client:
2、对比
-
对比常用字符集的区别
字符集 描述 utf8mb4_general_ci 不区分大小写,utf8mb4_general_cs区分大小写; utf8mb4_bin 将字符串每个字符串用二进制数据编译存储,区分大小写,而且可以存二进制的内容 utf8mb4_unicode_ci 校对规则仅部分支持Unicode校对规则算法,一些字符还是不能支持,但utf8mb4_unicode_ci也不能完全支持组合的记号 备注:
- ci 是 case insensitive, 即 “大小写不敏感”, a 和 A 会在字符判断中会被当做一样的。
- bin 是二进制, a 和 A 会别区别对待。(例如你运行:SELECT * FROM table WHERE txt = ‘a’, 那么在utf8mb4_bin中你就找不到 txt = ‘A’ 的那一行, 而 utf8mb4_general_ci 则可以。)
- utf8mb4_general_ci 是一个遗留的校对规则,不支持扩展,它仅能够在字符之间进行逐个比较。这意味着utf8mb4_general_ci校对规则进行的比较速度很快,但是与使用 utf8mb4_unicode_ci的校对规则相比,比较正确性较差。
-
应用上的差别
- 对于一种语言仅当使用 utf8mb4_unicode_ci 排序做的不好时,才执行与具体语言相关的utf8mb4字符集校对规则。例如,对于德语和法语,utf8mb4_unicode_ci工作的很好,因此不再需要为这两种语言创建特殊的utf8mb4校对规则。
- utf8mb4_general_ci 也适用德语、法语或者俄语,但会有不准。如果你的应用能够接受这些,那么应该使用 utf8mb4_general_ci,因为它速度快。否则,使用utf8mb4_unicode_ci,因为它比较准确。
我个人更加推荐utf8mb4_unicode_ci,因为相比CPU来说,它可能不足以成为考虑性能的因素,索引设计、SQL设计才是主战场。
3、 设置
- 修改数据库:
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci; - 修改表:
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; - 修改表字段:
ALTER TABLE table_name CHANGE column_name column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
评论区